 Học vui vẻ và post lên đây...
Học vui vẻ và post lên đây...
Quản lý index
0. Kế hoạch đề xuất
| Công việc | Thao tác | Tần suất |
|---|---|---|
| Index Missing | Create Indexes | Hàng tháng (Vào đêm) |
| Index Redundant, Replicate | Remove/Edit Indexes | Hàng tháng (Vào đêm) |
| Heap table, Index Scan | Xem xét và chỉnh sửa | Hàng tháng |
| Index Physical statistic report | Rebuild/reorganize/update statistic | Hàng tháng (Vào đêm) |
1. Index Missing
Sử dụng View có sẵn của SQL Server.
/* missing indexes */
SELECT DB_NAME(database_id) AS database_name
, OBJECT_NAME(object_id, database_id) AS table_name
, mid.equality_columns
, mid.inequality_columns
, mid.included_columns
, (migs.user_seeks + migs.user_scans) * migs.avg_user_impact AS Impact
, migs.avg_total_user_cost * (migs.avg_user_impact / 100.0) * (migs.user_seeks + migs.user_scans) AS Score
, migs.user_seeks
, migs.user_scans
FROM sys.dm_db_missing_index_details mid
INNER JOIN sys.dm_db_missing_index_groups mig ON mid.index_handle =
mig.index_handle
INNER JOIN sys.dm_db_missing_index_group_stats migs ON mig.index_group_handle = migs.group_handle
WHERE DB_NAME(database_id) = 'EASYBOOKS'
ORDER BY migs.avg_total_user_cost * (migs.avg_user_impact / 100.0) * (migs.user_seeks + migs.user_scans) DESC
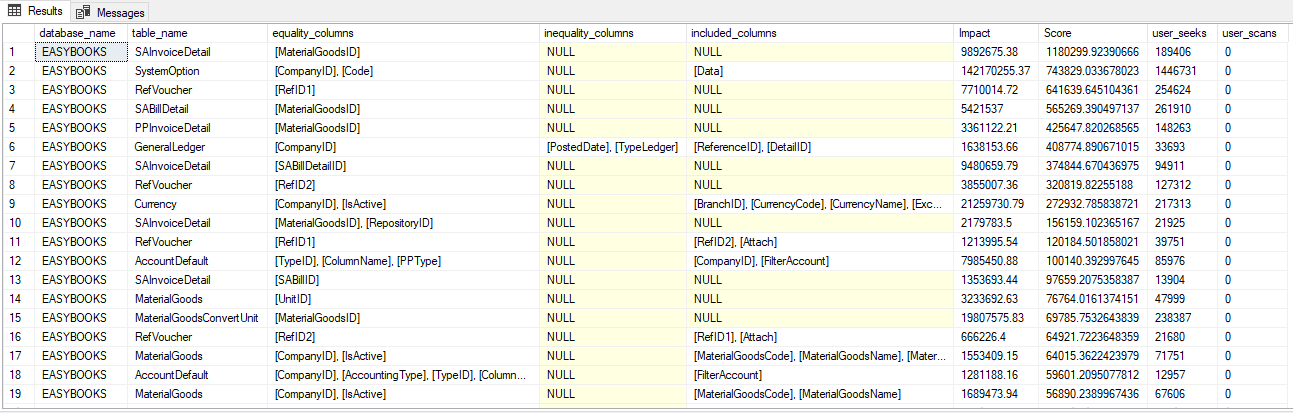
Như trong ví dụ trên:
equality_columns: là trường cần tạo index, phục vụ cho các câu query có điều kiện =. Ví dụ: WHERE SAInvoiceDetail.[MaterialGoodsID] = 123.
inequality_columns: là trường cần tạo index phục vụ cho các câu query có điều kiện > <> <. Ví dụ: WHERE SAInvoiceDetail.[MaterialGoodsID] > 123.
included_columns: là các trường có thể tạo kèm INCLUDE tức là covering index
impact: là số chi phí của các query có thể giảm được, khi tạo index.
score: điểm tạo ra thể hiện chi phí có thể cut-down dựa trên tổng số seek và scan từ index.
user_seeks và user_scan: là số lượt mà trước đây nếu có index như gợi ý, SQL Server có thể sử dụng.
- Khi tạo index ta liệt kê các column như gợi ý theo thứ tự:
equality_columnstrước, sau đó mới đếninequality_columnsvà cuối cùng làINCLUDEcác trườngincluded_columns
Ví dụ như trường hợp dưới đây:

thì index cần tạo như sau:
USE EASYBOOKS
GO
CREATE NONCLUSTERED INDEX idx_generalledger_companyid_posteddate_typeledger
ON GeneralLedger (CompanyID, PostedDate, TypeLedger)
INCLUDE (ReferenceID, DetailID);
Cuối cùng là không phải recommend nào trong missing_index cũng là hợp lý với DB, cần phải phân tích kỹ lợi/hại trước khi áp dụng các recommend này.
2. Redundant, Overlapping & Duplicate Index
Cũng sử dụng các View (DMV) có sẵn của SQLServer, lấy ra các Index dư thừa, không cần thiết.
- Đầu tiên, Duplicate Index là trường hợp các index được tạo trong DB giống hệt nhau về các trường (bao gồm cả INCLUDE)
- Redundant & Overlapping Index là trường hợp các index được xem là dư thừa ví dụ như các trường hợp sau:
CREATE NONCLUSTERED INDEX [IX_RunID_SiteID_DataSource_OutputType_PeriodType]
ON [dbo].[MyTable]
([RunID] ASC,
[SiteID] ASC,
[DataSource] ASC,
[OutputType] ASC,
[PeriodType] ASC
)
CREATE NONCLUSTERED INDEX [IX_RunID_SiteID_DataSource_OutputType_PeriodType_QuotaItemDriverID]
ON [dbo].[MyTable]
([RunID] ASC,
[SiteID] ASC,
[DataSource] ASC,
[OutputType] ASC,
[PeriodType] ASC,
[QuotaItemDriverID] ASC,
)
Rõ ràng khi tìm kiếm với điều kiện có hay không có trường [QuotaItemDriverID] thì cũng chỉ cần index 2 (vì statistic cũng có desity của 5 cột đầu tiên trong Density Vector). Khi đó index 1 được coi là dư thừa.
Hoặc trong 1 trường hợp khác
CREATE NONCLUSTERED INDEX [IX_RunID_SiteID_DataSource_OutputType_PeriodType_Includes] ON [dbo].[MyTable]
([RunID] ASC,
[SiteID] ASC,
[DataSource] ASC,
[OutputType] ASC,
[PeriodType] ASC
) INCLUDE ( [YTDRevenue], [MTDRevenue] )
CREATE NONCLUSTERED INDEX [IX_RunID_SiteID_DataSource_OutputType_PeriodType_QuotaItemDriverID_Includes] ON [dbo].[MyTable]([RunID] ASC,
[SiteID] ASC,
[DataSource] ASC,
[OutputType] ASC,
[PeriodType] ASC,
[QuotaItemDriverID] ASC,
) INCLUDE ( [SalespersonID], [MTDRevenue] )
Cả 2 index trên đều được coi là dư thừa nếu ta tạo 1 index khác có thể cover cả 2 index trên:
CREATE NONCLUSTERED INDEX [IX_RunID_SiteID_DataSource_OutputType_PeriodType_QuotaItemDriverID_Includes] ON [dbo].[MyTable]([RunID] ASC,
[SiteID] ASC,
[DataSource] ASC,
[OutputType] ASC,
[PeriodType] ASC,
[QuotaItemDriverID] ASC,
) INCLUDE ( [SalespersonID], [MTDRevenue], [YTDRevenue] )
Ta có thể tìm ra các index dư thừa, trùng lặp bằng cách tổng hợp từ DMV của SQL Server
/* Redundant & Overlapping & Duplicate indexes */
USE EASYBOOKS
GO
WITH IndexColumns AS
(
SELECT I.object_id AS TableObjectId
, OBJECT_SCHEMA_NAME(I.object_id) + '.' + OBJECT_NAME(I.object_id) AS TableName
, I.index_id AS IndexId
, I.name AS IndexName
, (IndexUsage.user_seeks + IndexUsage.user_scans + IndexUsage.user_lookups) AS IndexUsage
, IndexUsage.user_updates AS IndexUpdates
, (SELECT CASE is_included_column WHEN 1 THEN NULL ELSE column_id END AS [data()]
FROM sys.index_columns AS IndexColumns
WHERE IndexColumns.object_id = I.object_id
AND IndexColumns.index_id = I.index_id
ORDER BY index_column_id, column_id
FOR XML PATH('')
) AS ConcIndexColumnNrs
, (SELECT CASE is_included_column
WHEN 1 THEN NULL
ELSE COL_NAME(I.object_id, column_id) END AS [data()]
FROM sys.index_columns AS IndexColumns
WHERE IndexColumns.object_id = I.object_id
AND IndexColumns.index_id = I.index_id
ORDER BY index_column_id, column_id
FOR XML PATH('')
) AS ConcIndexColumnNames
, (SELECT CASE is_included_column WHEN 1 THEN column_id ELSE NULL END AS [data()]
FROM sys.index_columns AS IndexColumns
WHERE IndexColumns.object_id = I.object_id
AND IndexColumns.index_id = I.index_id
ORDER BY column_id
FOR XML PATH('')
) AS ConcIncludeColumnNrs
, (SELECT CASE is_included_column
WHEN 1 THEN COL_NAME(I.object_id, column_id)
ELSE NULL END AS [data()]
FROM sys.index_columns AS IndexColumns
WHERE IndexColumns.object_id = I.object_id
AND IndexColumns.index_id = I.index_id
ORDER BY column_id
FOR XML PATH('')
) AS ConcIncludeColumnNames
FROM sys.indexes AS I
LEFT OUTER JOIN sys.dm_db_index_usage_stats AS IndexUsage
ON IndexUsage.object_id = I.object_id
AND IndexUsage.index_id = I.index_id
AND IndexUsage.Database_id = db_id()
)
SELECT C1.TableName
, C1.IndexName AS 'Index1'
, C2.IndexName AS 'Index2'
, CASE
WHEN (C1.ConcIndexColumnNrs = C2.ConcIndexColumnNrs) AND (C1.ConcIncludeColumnNrs = C2.ConcIncludeColumnNrs)
THEN 'Exact duplicate'
WHEN (C1.ConcIndexColumnNrs = C2.ConcIndexColumnNrs) THEN 'Different includes'
ELSE 'Overlapping columns' END
-- , C1.ConcIndexColumnNrs
-- , C2.ConcIndexColumnNrs
, C1.ConcIndexColumnNames
, C2.ConcIndexColumnNames
-- , C1.ConcIncludeColumnNrs
-- , C2.ConcIncludeColumnNrs
, C1.ConcIncludeColumnNames
, C2.ConcIncludeColumnNames
, C1.IndexUsage
, C2.IndexUsage
, C1.IndexUpdates
, C2.IndexUpdates
, 'DROP INDEX ' + C2.IndexName + ' ON ' + C2.TableName AS Drop2
, 'DROP INDEX ' + C1.IndexName + ' ON ' + C1.TableName AS Drop1
FROM IndexColumns AS C1
INNER JOIN IndexColumns AS C2
ON (C1.TableObjectId = C2.TableObjectId)
AND (
-- exact: show lower IndexId as 1
(C1.IndexId < C2.IndexId
AND C1.ConcIndexColumnNrs = C2.ConcIndexColumnNrs
AND C1.ConcIncludeColumnNrs = C2.ConcIncludeColumnNrs)
-- different includes: show longer include as 1
OR (C1.ConcIndexColumnNrs = C2.ConcIndexColumnNrs
AND LEN(C1.ConcIncludeColumnNrs) > LEN(C2.ConcIncludeColumnNrs))
-- overlapping: show longer index as 1
OR (C1.IndexId <> C2.IndexId
AND C1.ConcIndexColumnNrs <> C2.ConcIndexColumnNrs
AND C1.ConcIndexColumnNrs like C2.ConcIndexColumnNrs + ' %')
)
ORDER BY C1.TableName, C1.ConcIndexColumnNrs
- Lưu ý ta phải run query trên DB cần xem xét, ví dụ
USE EASYBOOKS
Vì có nhiều trường hiển thị trong kết quả, ta cắt ra thành 2 ảnh để tiện xem xét ở đây:


Cũng không cần phải giải thích từng trường trong bảng kết quả vì nó tương đối khá rõ ràng rồi.
Cũng như trường hợp missingIndex, ta cần xem xét kỹ các thống kê hay recommend ở đây có thích hợp với DB đang sử dụng hay không.
3. Index Usage
Một công việc maintain cần thiết cho các index trong DB đó là thống kê tình trạng sử dụng của tất cả index. Cùng với đó để xem xét các trường hợp có thể action để tối ưu hiệu năng của hệ thống.
/* Index usage statistics */
SELECT OBJECT_NAME(IX.OBJECT_ID) Table_Name
, IX.name AS Index_Name
, IX.type_desc Index_Type
, SUM(PS.[used_page_count]) * 8 IndexSizeKB
, IXUS.user_seeks AS NumOfSeeks
, IXUS.user_scans AS NumOfScans
, (IXUS.user_seeks + IXUS.user_scans) AS TotalSeeksAndScans
, IXUS.user_lookups AS NumOfLookups
, IXUS.user_updates AS NumOfUpdates
, IXUS.last_user_seek AS LastSeek
, IXUS.last_user_scan AS LastScan
, IXUS.last_user_lookup AS LastLookup
, IXUS.last_user_update AS LastUpdate
FROM sys.indexes IX
INNER JOIN sys.dm_db_index_usage_stats IXUS ON IXUS.index_id = IX.index_id AND IXUS.OBJECT_ID = IX.OBJECT_ID
INNER JOIN sys.dm_db_partition_stats PS on PS.object_id = IX.object_id
WHERE OBJECTPROPERTY(IX.OBJECT_ID, 'IsUserTable') = 1
-- AND IX.type_desc = 'HEAP'
GROUP BY OBJECT_NAME(IX.OBJECT_ID), IX.name, IX.type_desc, IXUS.user_seeks, IXUS.user_scans, IXUS.user_lookups,
IXUS.user_updates, IXUS.last_user_seek, IXUS.last_user_scan, IXUS.last_user_lookup, IXUS.last_user_update
ORDER BY IndexSizeKB DESC
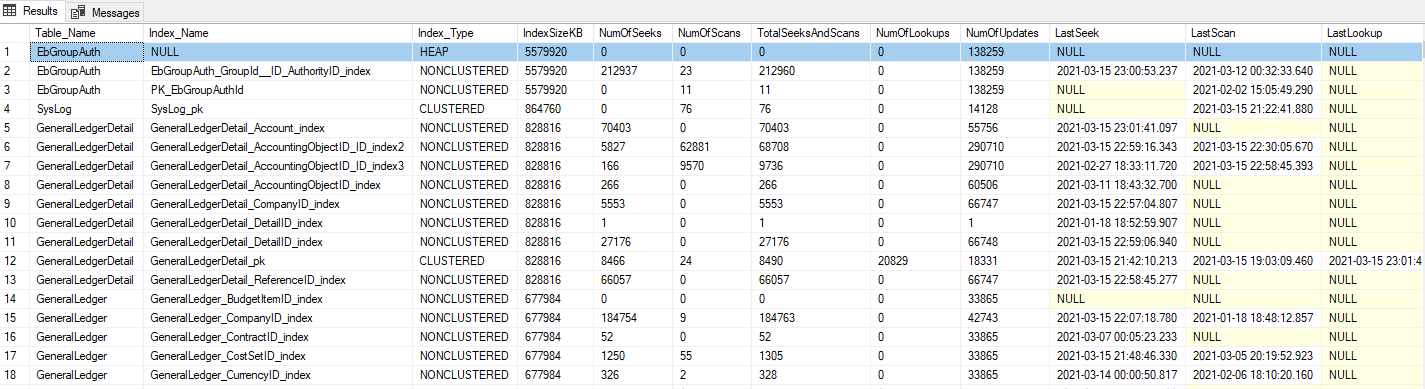
Từ kết quả trên ta có thể hình thành các tiêu chí maintain như sau:
3.1. Xử lý các HEAP TABLE
Heap table là các bảng không có Clustered Index. Heap Table không được sắp xếp, do đó, trường hợp SQL Server phải scan trong heap table sẽ tăng cost cho quá trình scan (so với bảng có Clustered Index), ảnh hưởng tiêu cực đến hiệu năng hệ thống.
Liệt kê heap Table bằng cách thêm điều kiện WHERE vào câu query thống kê ở trên:
AND IX.type_desc = 'HEAP'
Cách xử lý là thêm Clustered Index vào bảng thiếu
CREATE CLUSTERED INDEX ...
hoặc sửa Primary Key đang có thành Clustered Index (Vì một số lý do lúc tạo bảng lại quy định Primary Key là Nonclustered)
DROP INDEX ... ON ...
ALTER TABLE ... ADD CONSTRAINT your_name PRIMARY KEY CLUSTERED (your_col)
3.2. Xem xét các Index ít được sử dụng
Bằng cách dựa vào thống kê số lần Seek + Scan trên Index, chúng ta có thể liệt kê những Index ít được sử dụng. Cũng với câu query thống kê ở trên, tuy nhiên ORDER khác đi:
WHERE ...
AND IX.type_desc = 'NONCLUSTERED'
...
ORDER BY TotalSeeksAndScans ASC

Trong ví dụ trên ta có thể thấy một số Index tạo ra, không được sử dụng lần nào, nhưng chiếm đến hơn 600MB hoặc thậm chí 800MB lưu trữ.
Việc loại bỏ các index cũng cần được xem xét lại cẩn thận
Chúng ta có thể xem xét trong các plan của PlanCache hay QueryStore bằng các câu query ở đây.
3.3. Xem xét các Index có lượng Scan lớn
Về cơ bản, Index Seek luôn là tối ưu nhất cho hiệu năng hệ thống. Một số trường hợp bắt buộc SQLServer phải Scan index tuy nhiên có một vài trường hợp là do sai sót khi phát triển.
Liệt kê các Index có lượng Scan lớn bằng query ở trên, thay đổi ORDER:
WHERE ...
AND IX.type_desc = 'NONCLUSTERED'
...
ORDER BY NumOfScans DESC
Việc khử IndexScan là một câu chuyện dài và có thể bàn đến trong một bài viết khác. Có thể điểm qua 1 vài sai sót dẫn đến IndexScan (thay vì IndexSeek):
- Sai thứ tự cột trong index: cột đầu tiên không phải là cột đang tìm kiếm trong query, không phải là cột có tính selective cao nhất trong tổ hợp.
- Điều kiện tìm kiếm WHERE đang là
non sargable:<>, !=, !>, !<, NOT EXISTS, NOT IN, NOT LIKE IN, OR, LIKE ‘%<literal>’ - Sử dụng vòng lặp không đúng cách: lạm dụng CURSOR, WHILE,…
- Sử dụng
SELECT *trong khi chỉ cần trả về một số trường trong bảng. - Index chưa phải là Covering Index: thiếu
INCLUDEcác trường cần SELECT. - Sử dụng các FUNCTION ở điều kiện
WHEREhay sử dụng các View lồng nhau.
## 4. Index Physical Statistic Report
Bộ built-in báo cáo của SQL Server cho ta check tình hình lưu trữ của các Index của từng DB.
Tư tưởng là ta có thể tối ưu hiệu năng cho các Index bằng cách sắp xếp/rebuild lại các Index đang bị phân mảnh (Index Fragmentation) quá nhiều trong Disk/RAM của hệ thống.
Tạo báo cáo trên SSMS:
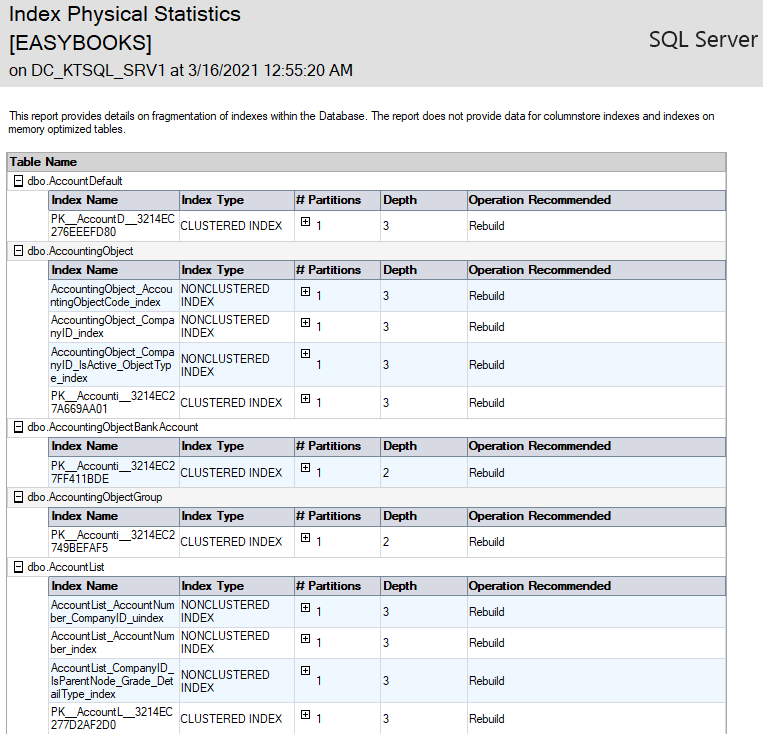
Dựa vào khuyến nghị của báo cáo ta có thể thấy các Index cần phải rebuid hoặc reorganize.
Đối với các hệ thống dịch vụ có thời điểm ít sử dụng (peak-time), chúng ta có thể rebuild vào thời điểm đó và cập nhật Statistic của index.
--điều kiện ONLINE = ON cho phép bỏ qua việc lock index/table khi rebuild
ALTER INDEX index_name ON @Table REBUILD WITH (ONLINE = ON)
...
--rebuild toàn bộ index trong bảng với ALL
ALTER INDEX ALL ON @Table REBUILD WITH (ONLINE = ON)*
...
ALTER INDEX index_name REORGANIZE
--reorganize toàn bộ index trong bảng với ALL
ALTER INDEX ALL REORGANIZE
Cập nhật Statistics sau khi Rebuild/Reorganize:
--trong peak-time, nên update với fullscan để stats được chính xác nhất
UPDATE STATISTICS table_name WITH FULLSCAN;
--nếu update cụ thể stat
UPDATE STATISTICS table_name statistic_name WITH FULLSCAN;
Việc rebuild/reorganize luôn đảm bảo tối ưu hiệu năng (vì loại bỏ IndexFragmentation), nó chỉ gây ảnh hưởng trong thời điểm mà CCU cao